Fornax Science Console#
What is the Fornax Science Console?#
The Fornax Science Console is a NASA-funded web-based application that provides access to a limited amount of cloud computing via JupyterLab, which offers access to Jupyter Notebooks, Jupyter Console, and the terminal (command line). Users will need to register to login to the system, but usage is free. Once logged in, users will have access to data sets curated by repositories around the world, and can upload moderate amounts of private data. To get started quickly, users can choose from a variety of example Jupyter notebooks as well as pre-installed software environments. These can be modified to suit user needs.
The Fornax Science Console supports many astronomical use cases, but users will find it especially beneficial for analyses
on large cloud-hosted data sets that would be cumbersome to download;
that require complicated software pre-installed on the platform; or
that are parallelizable and require more compute than they currently have access to.
Fornax Science Console basic capabilities and selection guidelines#
After logging in, users will be presented with choices for their working environment.
Server type: the amount of compute (CPUs) and memory (RAM) available is configurable. Options are briefly described below.
Environment: the software environment including the operating system, system library versions, and pre-installed software selections.
The compute size you select largely determines the costs you will accrue while it is running. We therefore need our users to be more conscious of the compute you are using than you would be on your own hardware. We ask users to follow these guidelines:
You will have a choice of server types. Please test your use case on the smallest server that can serve as a test, and run tests with a limited scope (e.g., number of sources, iterations, etc.). Only expand the scope and/or select a larger server when you have successfully tested the smaller case.
Please also note that if you start an instance, closing your browser window does not necessarily stop the instance you started. Especially with the larger instances, please explicitly use the “Stop My Server” button (under File->Hub Control Panel) when done.
Any time you need to use the biggest 128-core compute instance, please reach out to the Help Desk for explicit permission before starting it. This will help us to be aware of resource usage for this development system, which does not yet have fully automated resource usage guardrails. Give us a brief idea of what the science use case is and an estimate for the total run time. Note that if your job (or jobs) runs significantly longer than we expect, we may contact you about terminating it. If you need to stop and restart your instance, you don’t need to get permission every time as long as you are still within the original estimated total run time. If you need more time than expected, please write to the help desk with a brief justification. Our review process is more about visibility than control, so you’ll probably be approved.
The compute options depend upon Server type selected:
CPUs: Users can choose between 4 - 16 CPUs. These are useful for smaller analyses and to test out larger analyses. Once a user has completed testing and is ready to scale up an analysis, they can request up to 128 CPUs.
RAM: Users can choose between 8 - 64 GB of RAM. Up to 512 GB of RAM is available upon request (instructions below).
User Storage: Upon logging in, users will have access to 10 GB of storage; additional storage is available upon request.
GPUs: There are currently no GPUs available.
Software environment options:
A base environment contains common astronomy libraries such as Astropy.
The forced photometry tool called Tractor is available in a customized environment.
The HEASoft high-energy astrophysics software is available in another customized environment.
More environments will be created as need.
Data access within the Fornax Science Console#
Users of the Fornax Science Console will have access to data curated and published by data repositories around the world.
The NASA Astrophysics Mission Archives (HEASARC, IRSA, MAST) offer curated datasets through the AWS Open Data program, which can be found by searching https://registry.opendata.aws/.
In addition, most data archives, including NASA archives and others around the world, provide access through application program interfaces (APIs), which can be invoked by users of the Fornax Science Console through standard Python (e.g. astroquery, pyvo) or command line methods (e.g. wget, curl).
Quick Start Guide#
1. Get an account on the Fornax Science Console#
The platform is currently available by invitation only.
2. Log into the Fornax Science Console#
Once you have your login credentials, enter them at:
https://science-console.fornax.smce.nasa.gov/
Choose the software environment: You will be given the option of choosing from a menu of software container images. Currently we offer to two images:
Astrophysics Default Image (most users should choose this)
High Energy Astrophysics Image
Choose a compute instance: You will be offered 2 primary options for the size of the compute. Please use the
Standardsize for writing, debugging, or testing code before switching toLargesize for full runs of code at scale. Some of the options are marked as “Use with approval”. Please contact the person that invited you to the platform to obtain permission to use these instances.Click “Start”. In a few moments, you will find yourself in JupyterLab.
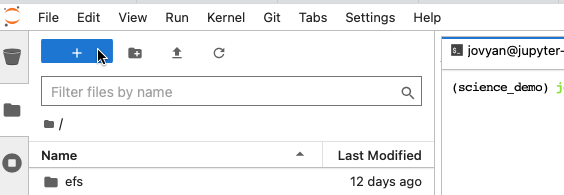
3. Start a new notebook.#
Click on the the blue
+in the upper left of the JupyterLab window to open the launcher, which will give you the option to open a Notebook or a Terminal. Choose the “science_demo” kernel under “Notebook”. This will open a new notebook that you can start coding in and run on the platform.
4. End your JupyterHub session.#
Before logging out, please shut down your server. This is an important step which insures the server you are using doesn’t keep running in the background, thereby wasting resources.
Go to the
FileMenu and click onhub control panelas in the below image, which will bring up the option tostop my server(in red). After stopping the server, pleaselogoutin the upper right of the JupyterHub window.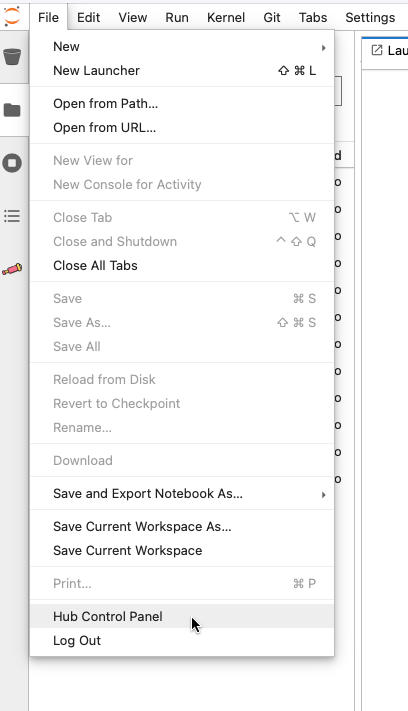
Starting & Monitoring Analyses#
How can I tell which computing resources are available on the Fornax Science Console?#
You will have access to the CPU and RAM resources selected upon startup in Fornax. It is possible to query in a terminal window to find the amount of CPU or RAM.
In JupyterHub, open a terminal window, and use one of the below commands:
nprocwill give you the number of processorscat /proc/cpuinfowill give you more detailed info on the processorsfree -hwill give the amount of RAM available/usedcat /proc/meminfowill give more detailed info on the amount of RAM available/usedtopgives info on both CPU and RAM usage. Some numerical packages (e.g. numpy) use multithreading, so you may see that the CPU usage is more 100%. That means more than one CPU is used. You can see the individual CPU usage by pressing 1 while thetopcommand is running.
Please use MyST Markdown .md files instead of .ipynb for Jupyter notebooks#
Using .md (specifically MyST Markdown) files for Jupyter notebooks in GitHub repositories offers significant advantages over traditional .ipynb files, particularly for astronomers and researchers collaborating on code-intensive projects. The primary benefit is vastly improved readability during code reviews and version control. Unlike .ipynb files, which store output, metadata, and code in a convoluted JSON format, .md files present code and text in a clean, diff-friendly format. This makes it easier to track changes in pull requests, compare versions, and conduct meaningful code reviews, which is essential for maintaining high-quality, reproducible research code. Additionally, Markdown files integrate seamlessly with Jupytext, allowing them to function as fully interactive notebooks within JupyterLab, offering the same user experience without the drawbacks of .ipynb files. To read more about the differences, we refer to the JupyterBook Ecosystem documentation.
Furthermore, using markdown files promotes best practices for open science and educational resources. Many organizations, including NumPy are using Markdown-based notebooks to enhance accessibility and collaboration. Markdown is a lightweight format that supports rich formatting, code execution, and the inclusion of outputs while remaining easily editable in any text editor. This ensures that research notebooks remain both human-readable and machine-readable, enabling astronomers to share code and results more effectively with collaborators and the wider scientific community.
On the Fornax Science Console all required dependencies are pre-installed. If you wish to work with MyST Markdown notebooks on your local JupyterLab and to have the same user experience as with the older file format, the following two dependencies are required to be installed: the jupytext Python library, and the jupyterlab-myst JupyterLab extension.
Instructions for Using .md Files in JupyterLab#
Starting a New Notebook as a
.mdFile:In JupyterLab, when creating a new notebook, choose
.mdinstead of.ipynbto ensure better version control and code reviewability.
Opening an Existing
.mdFile as a Jupyter Notebook:Navigate to the
.mdfile in the JupyterLab file browser.Right-click the file, select
Open With, and chooseNotebookorJupytext Notebook.This will open the Markdown file in a notebook interface with cells and execution capabilities, just like a traditional .ipynb notebook.
Converting an Existing .ipynb Notebook to MyST Markdown:
If you have an existing .ipynb file that you want to add to the repository, convert it to markdown using Jupytext:
jupytext --to md:myst notebook.ipynbBy following these instructions, you can leverage the benefits of Markdown files while maintaining the full functionality of Jupyter notebooks.
How can I tell if I am close to using up my allocation of compute and storage resources?#
Under construction.
How will my analysis be affected by memory limitations?#
If your workload exceeds your server size, your server may be allowed to use additional resources temporarily. This can be convenient but should not be relied on. In particular, be aware that your job may be killed automatically and without warning if its RAM needs exceed the allotted memory. This behavior is not specific to Fornax or AWS, but users may encounter it more often on the science console due to the flexible machine sizing options. (Your laptop needs to have the max amount of memory that you will ever use while working on it. On the science console, you can choose a different server size every time you start it up – this is much more efficient, but also requires you to be more aware of how much CPU and RAM your tasks need.)
What is a kernel and how do I choose one?#
Under Construction: In Jupyter, kernels are the background processes that execute cells and return results for display. To select the kernel on which you want to run your Notebook, go to the Kernel menu and choose Change Kernel. You can also click directly on the name of the active kernel to switch to another one. The bottom of the JupyterLab window lists the github branch as well as the name of the kernel in use. The kernel is listed as either ‘idle’ or ‘busy’, which is useful to know if your kernel is working or has crashed.
What is the Dask extension and how do I use it?#
Dask is a python library for parallel computing,
roughly similar to the multiprocessing standard library.
The Fornax Science Console includes the
Dask JupyterLab Extension which
can be used to manage a Dask cluster and monitor the progress of submitted
functions, all from within JupyterLab.
The charts that make up Dask’s monitoring dashboard are embedded directly in
JupyterLab panes which can be moved around into custom arrangements.
Here are some chart examples:

Quick-start instructions:
On the left-hand side of the Console, click the Dask icon that looks like this:

Scroll down and click “+NEW” next to “CLUSTERS” to start a new cluster.
Right above that, once the cluster starts, you’ll see a column of yellow buttons appear with the names of available charts. Click on any of them and a new tab will open showing the selected chart. You can drag and drop the tab to move it somewhere else on the screen. In the screenshot above, several charts are open and arranged next to each other.
Start or restart the kernel for the notebook you’re working in so that it will recognize the cluster.
Submit functions to Dask as normal (Dask Quickstart) and you will see the charts update as the work progresses.
Does work persist between sessions?#
Files in your home directory will persist between sessions.
pip installs will persist across kernel restarts, but not across logging out and back in.
If you want software installs to be persistent, consider setting up an environment: See below under “Making a conda environment that persists across sessions”
Save your work!#
The Science Console is primarily intended for interactive use and will cull
sessions which appear to be inactive. Your session will not be culled if there
is CPU activity. Keeping your computer from sleeping will also keep your
session active; regardless of any interactivity.
If you want a notebook or script to run longer than about 15 minutes and
there is no processing in your notebook or you will not be interacting with the
Console, running top during that time can help keep the session active.
Under construction: how long is the period of inactivity that gets culled? 15 minutes.
How can I save my notebook as a Python script?#
There are multiple ways to convert a notebook to a Python script, the easiest
is to use jupytext on the command line. It is installed on Fornax, but if you
work on your local computer, you may need to pip install it first:
jupytext --to script <your_notebook_file>
How can I run a notebook non-interactively?#
Under Construction.
Can I use VS code on Fornax?#
Yes! To open VS code on Fornax, first start up a compute session from the science console. To do this, from the dashboard, on the left hand side menu, click on JupyterHub under Compute. Once jupyterhub loads, click on the blue plus sign in the upper left corner. In case you are in some other tab, make sure you are in the File browser tab which is shown by the file symbol in the furthest left column. The blue plus sign takes you to the launcher where you will see “VS Code” in the top row under “Notebook”. Clicking on this link will automatically open another window where you can use VS Code for the web.
Data Management#
How can I upload my own data for use with compute provided by the Fornax Science Console?#
The uparrow in the upper left allows you to upload data. If it is a large amount of data, consider creating a zip or tar archive first. From within JupyterLab, you can also use a terminal to transfer data with the usual methods (scp, wget, curl should all work). The current (Feb 2024) default storage limit for uploaded data is 10GB (Feb 2024). When you log into the science console for the first time, the active directory is your $HOME directory. It contains preexisting folders like efs/ with shared data. You may also create your own directories and files here. Your edits outside of the shared folders are not visible to other users.
How can I access data that has been hosted on the cloud by the Fornax archives?#
Is there a way access data in a Box account from the Fornax Science Console?#
Any publicly accessible web service can be reached from Fornax through the HTTPS protocol, e.g., APIs, wget, etc.
Is there a way to access data from an AWS bucket?#
Any publicly available bucket is visible from Fornax as it would be on your laptop. If you require an access key to see into the bucket from your laptop, you will also need that on Fornax.
How can I open a plot (e.g. png, pdf) that I generated in a notebook or uploaded?#
Double-clicking on a png or PDF in the file browser will open it in a new tab.
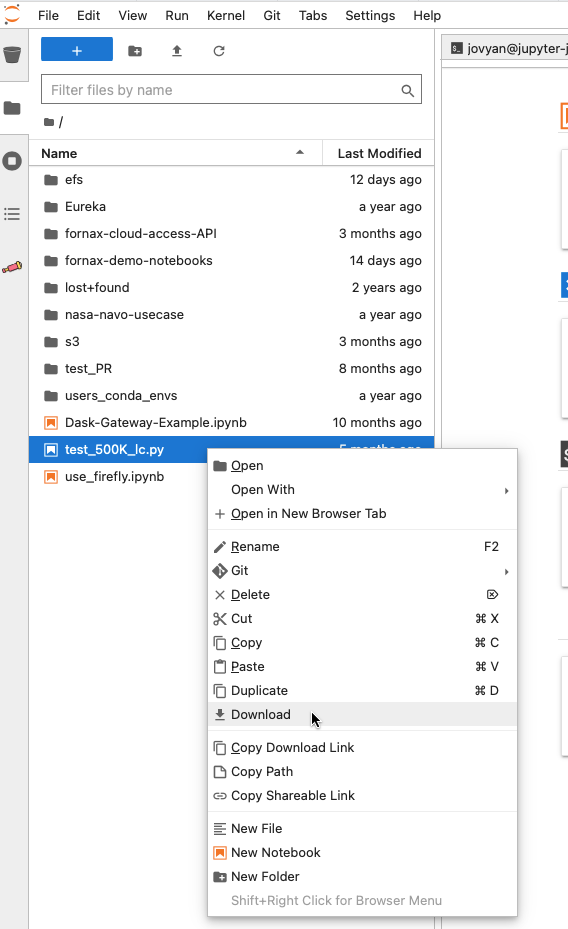
How do I download data from the Fornax Science Console to my local machine?#
If it is a large amount of data, consider creating a zip or tar archive first. If it is a small file, you can right click on the file name in the file browser and scroll to Download.
Managing Software#
How can I get a list of what software is pre-installed on the Fornax Science Console?#
Software is installed in Miniconda environments. You can use “conda list” from a Terminal within the Fornax Science Console to list the contents of each environment.
Can I install my own software on the Fornax Science Console?#
Persistent User-Installed Software
If the pre-installed environments don’t have the software you need, you can create your own persistent environment available across multiple sessions. Follow the instructions in the conda documentation, specifically managing environments.
Non-persistent User-Installed Software
You can !pip install your favorite software from inside a notebook. This installed software will persist through kernel restarts, but will not be persistent if you stop your server and restart it (logging out and back in) unless you specify the - - user option, which will put the software in your home directory. Note that an install done in one compute environment may or may not work in a container opened using another environment, even if the directory is still there. Conda environments are useful to manage these.
For the tutorial notebooks we tend to have a requirements.txt file in the repo which lists all the software dependencies. Then the first line in the notebook is
!pip install -r requirements.txtThat way other people can run the notebook and will know which software is involved.
There is a limit on the space a user has access to, but not the number of packages, and packages are usually small.
What is the terminal command to list package version info using pip?#
pip show package-name
Is it possible to bring my own docker image?#
This is not currently possible.
Is it possible to do code development in emacs or vi or some other IDE?#
Emacs or vi is possible from the terminal.
The JupyterLab interface also has its own editor.
If you prefer to develop elsewhere, you can push your changes to a publicly available repo (e.g., GitHub) and synchronize that to a location on your home directory on Fornax.
Will notebooks that run on Fornax also work on my laptop?#
In general, yes, but you need to have a Python environment setup in the same way as on it is on Fornax.
See below under “Can I run the container from Fornax on my own personal computer/laptop?”
Is it possible to launch apps from icons? Like MOPEX or SPICE#
These apps are unavailable in Fornax
Is it possible to run licensed software (IDL) in Fornax?#
licensed software is not possible in Fornax
Is it possible to run the container from Fornax on my own personal computer/laptop?#
Yes. The images are all on the AWS Elastic Container Registry.
Under Construction: Need a link and more instructions
Examples and Tutorials#
Fully worked science use cases#
Cloud#
Optimizing code for CPU usage (CPU profiling)#
profiling within Fornax is possible, however visualizing the profile is not yet possible
profiling needs to be done on a .py script, and not a Jupyter notebook
sample command on the Fornax command line:
python -m cProfile -o output_profile_name.prof code_name.pyThen download the .prof file
On your local computer command line:
python -m snakeviz output_profile_name.profdocumentation for SnakeViz: https://jiffyclub.github.io/snakeviz/
This really only looks at CPU usage
Optimizing code for memory usage (memory profiling)#
inside the notebook:
pip install -U memory_profilerfrom memory_profiler import profileabove the function you want to check add this line: @profile
run the script: python -m memory_profiler
.py > mem_prof.txt
Optimizing code for multiple CPUs with parallelization#
Python built in multiprocessing
Our scale up notebook is a tutorial on parallelization of generating multiwavelength light curves with tools, tips, and suggestions relevant to many tasks.
MAST science examples#
HEASARC sciserver_cookbooks#
Cross matching two large catalogs#
Work with theoretical catalogs#
How can I contribute to existing Open-Source Fornax notebook tutorials?#
open issue or PR on Fornax Github repo
Suggestions for accesible color palettes for plotting#
Troubleshooting#
If my internet connection goes away or is intermittent - what happens to the running notebook?
Restart kernel will solve some problems, especially if the cells were run out of order
Under the
kernelmenu:restart kernel...
Restart Fornax - will solve version issues if packages with different versions were loaded since these won’t persist across Fornax restarts
Getting Help#
ask your peers: User forum at #fornax-users slack channel
ask Fornax Helpdesk
email fornax-helpdesk@lists.nasa.gov
If you are reporting a problem or suspected bug, please include as much of the following information as possible. This will help minimize the time it takes for us to diagnose the problem and get you an answer. A template for how to craft these bug reports is here and we highly suggest you check this out before submitting.
- date and time (with timezone) the problem occurred - web browser (name and version) you are using to connect to the Fornax Science Console (e.g., Chrome 125.0.64422.142) - where in the Fornax Science Console this happened (e.g., while running a notebook in JupyterHub; while using the Dask extension; etc.) - what you were doing when the problem occurred - what you expected to have happen - what happened instead - include any errors messages or info that were produced - please include any additional information you feel is relevant (e.g., successfully did this same thing previously on date NN at time NN and it worked then) - if you have logs or a traceback, please include them
Parallel and Distributed Processing#
Since one of the main drivers for using Fornax is the advantage of multiple CPUs, we provide here additional information on how to efficiently use those CPUs.
Terminology#
CPU:
Central Processing Unit. Quality and number of CPU determines compute power – the rate at which computations can be performed.
Node
A single machine within a network of machines used for distributed processing.
Parallel or Distributed Processing
Parallel: Running >1 process/job concurrently. Distributed: Running a set of processes/jobs by farming them out to a network of compute nodes; Many of these jobs may run in parallel. (Distinction between parallel and distributed and is not deeply important here.)
RAM
Working memory in a machine, node, or network. Amount of RAM determines how much data can be loaded in-memory simultaneously.
Worker
An entity that completes a chunk of work (data + instructions). It runs in the background and must be managed using (e.g.,) python
multiprocessingor Dask.
When should I use distributed or parallel processing?#
Your dataset is very large, but could be split into subsets that can be processed individually.
The forced photometry notebook is an example of this. It gathers a large number of images and then processes them all using the same piece of code (photometry extraction). The pipeline is parallelized by running workers that execute the same code on different images.
Your computations/operations take a long time, but can be split into subsets that are independent from each other (the input to one does not depend on the output of another).
The light curve generator notebook is an example of this. It gathers a sample of objects and then runs several, independent pieces of code (calls to different archives to retrieve light curves) on the full sample. The pipeline is parallelized by running workers that execute different pieces of code on the same object sample.
Distributed processing with Dask DataFrames – basic concepts#
Dask:
Dask is a python library to manage parallel and distributed computing. Its responsibilities include:
Farm out chunks of work (data + instructions) to be completed in the background.
Manage the workers, the memory usage, etc.
Collect and consolidate worker results and return them to the user.
Pandas DataFrames:
There is no inherent size limit for a Pandas DataFrame other than the amount of RAM available.
Some operations that are trivial on a small-ish DataFrame (e.g., sorting) become costly when the DataFrame is large. In addition to DataFrame size, an essential factor will be the quality and number of CPU.
Dask DataFrame:
You can think of this as a wrapper for Pandas DataFrames:
Pandas handles the actual data (in memory) and most of the computations. Each worker uses it’s own Pandas DataFrame.
Dask orchestrates the process. It tells each worker which chunk of the full dataset (which is not in memory) to use, and which Pandas operations to execute.
The user gives instructions to Dask (by calling Dask methods), not to Pandas.
There are Dask-equivalents of many Pandas methods, though they sometimes behave differently due to the need to handle very large datasets or datasets that are not in-memory.
Performance implications to be aware of:
The Dask DataFrame index can make a big difference in efficiency. For large datasets, it can be highly advantageous to determine the “right” index (based on the desired chunking and/or computations). Set and sort the index before performing the computations, and don’t change it later on unless really necessary.
(others?)
Additional Resources#
New to Python? -
Fornax is the collaboration of three NASA archives